干货分享|RAG 知识库如何系统评测?核心指标与实战优化全解析(下)
 2026-05-29
2026-05-29
引言
上篇我们系统梳理了RAG知识库的四大维度多项评测指标。但指标体系终究是「标尺」,真正的价值在于用这把标尺去测量真实系统、发现瓶颈、指导优化。本篇将完整呈现多轮递进式评测实践——从测试集构建、评测平台配置,到基础基线、组合优化的全过程,揭示那些「意料之外、情理之中」的关键发现,并以边界智能打造的企业级智能体知识库「睿阁」为代表,介绍如何通过Agent智能体+结构化数据库的架构重塑,让 RAG 知识库真正满足企业级需求。
一、评测实践:从基础基线到组合优化
1.1 评测方案设计
1.1.1 测试集构建
为全面检验 RAG 系统的能力边界,我们构建了大规模多维度测试用例集,覆盖了包括知识时效性、精确数值查询、逻辑理解能力、图像 OCR 识别、印章干扰识别、噪声干扰识别、电费账单等专业文档识别、跨页信息识别等在内的 20+个典型业务场景。
1.1.2 评测工具链
- Ragas框架:标准化评估 Answer Correctness、Faithfulness、Context Precision、Context Recall 等核心指标
- 自定义评估指标:基于 LLM 的my_correctness_critique,评估回答是否包含标准答案核心事实,对额外信息更宽容
- Langfuse:全链路可观测性追踪,记录每次检索上下文、生成答案和评估得分
- ROUGE/BLEU:传统 NLP 指标作为检索召回率的补充度量
1.1.3 评测平台与配置
- 评测环境:基于企业级 RAG 知识库的标准部署配置,支持向量检索、Agent 智能体查询、结构化数据库查询等多种回答路径。
- 评测执行方式:每个核心指标执行多轮测试以增加可靠性,轮次稳定性通过标准差衡量。评测过程中,每个核心指标均进行多轮测试,确保结果可复现。
1.2 基础评测发现
首轮评测在基础配置下进行(未引入 Reranker、Agent 查询经验、结构化数据库等),作为后续优化的对照基准。
- 答案正确性:整体处于中等偏上水平,主要失分场景包括:时效性问题、图像与噪声干扰、中英文混合中的语义理解偏差等。
- 事实一致性:表现较好,说明基础配置下系统已能较好忠实于检索上下文,但仍有少数用例存在事实漂移。
- 检索精确度:是所有指标中最薄弱的一环——检索结果中包含大量无关片段(如网页导航栏 HTML、冗长表格、噪声页眉页脚),严重干扰答案生成质量,面临典型的「召回广但噪声大」问题。
基于首轮评测结果,明确了三条核心优化路径:改善检索排序质量、提升时效性数据处理能力、优化文档预处理与切片策略。
1.3 多轮优化:从单一手段到系统组合
我们进行了多轮递进式优化评测,呈现出一条清晰的「先降后升」的 V 型反弹趋势。
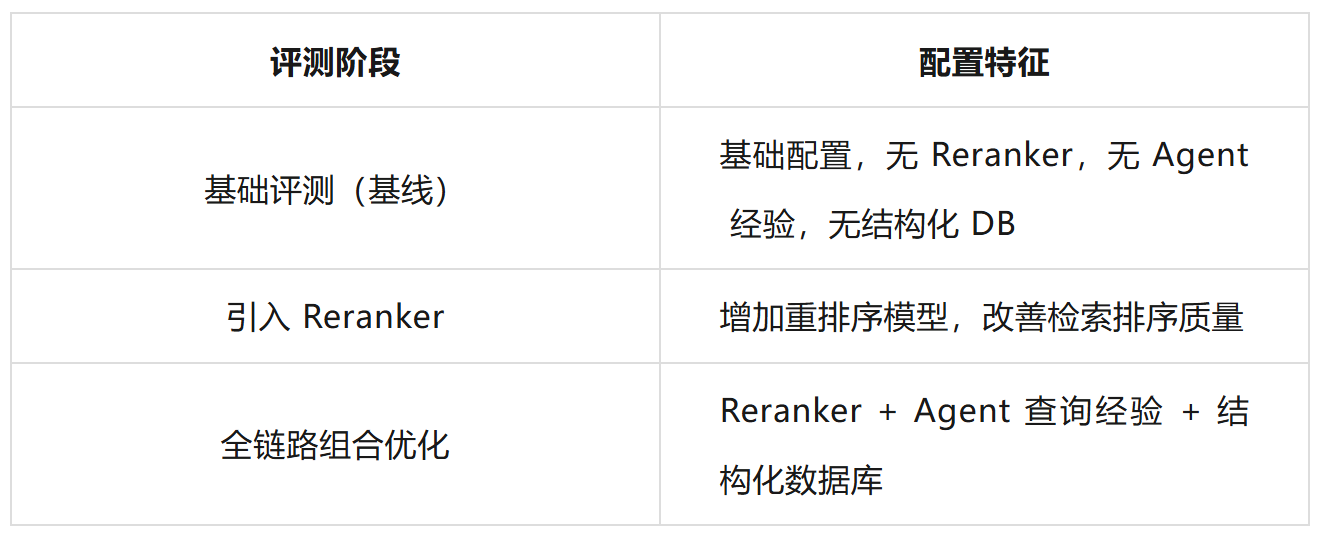
核心发现一:单一优化手段效果有限,甚至可能倒退
仅引入 Reranker 重排序模型后,检索排序质量有所改善,但答案正确性反而下降。原因在于:排序变化导致部分用例引用的上下文与答案的匹配模式改变,反而降低了最终回答质量。事实一致性和检索召回率也出现下滑——Reranker 可能过滤掉了部分相关但排序较低的文档,导致语义覆盖度下降。
这揭示了一个重要规律:仅靠检索层面的优化无法解决 RAG 系统的根本问题。
核心发现二:组合优化的协同增益显著
在 Reranker 基础上增加 Agent 查询经验和结构化数据库后,所有核心指标出现强劲的 V 型反弹:
在自定义评估体系下(基于LLM的核心事实判断,对 Agent 过程性描述更宽容),答案正确性的自定义评估得分从基础配置的 0.81 提升至 0.90(+11.1%),率先突破 0.9 大关。从轮次稳定性看,优化后稳定用例和较稳定用例合计占比超过三分之二,说明系统在多轮重复查询下能给出基本一致的正确回答。
这一变化的两个核心驱动力:
1.Agent 智能体:能自主判断查询路径——时效性数据(如最新 LPR)直接从结构化数据库查询,政策解读类问题走知识库检索。这种“分而治之”的策略大幅提升了准确性。
2.结构化数据库查询:对 LPR 利率、汇率等结构化数据,Agent 直接从数据表查询(如lpr_history),避免了传统切片检索的不确定性,从「模糊匹配」变为「精准查询」,这是回答正确性大幅提升的根本原因。
核心发现三:传统评估指标在 Agent 模式下的局限性
Agent 模式下,回答包含大量过程性描述(如查询步骤、数据来源说明),这些内容在传统 Ragas 框架中被标记为「误报」,导致评分与实际质量出现偏差。自定义评估(基于 LLM 的核心事实判断)能更准确地反映实际质量。这提示我们:评测指标体系本身也需要随着系统架构的演进而迭代。
1.4 典型问题剖析(大规模测试)
- 知识时效性:多版本数据共存时,系统难以识别“最新”数据或进行时序分析(如同比增长)。根因在于向量检索匹配语义相似而非时间最新。
- 图像与文档识别(问题最集中):
- 印章/背景色/小字/图表标记/验证码/手写等场景下 OCR 准确率大幅下降。
- 表格提取失败(非制式表格、注解标记关联困难)。
- 跨页与跨表格:跨页信息、跨表数据、注解标记与实际内容关联困难。
- 多语言与逻辑:英语提问+中文数据查询失败;多文档对比混淆;股权穿透计算不准。
1.5 检索指标的适用性反思
Agent 使用结构化数据库直接查询时,检索上下文仅为查询指导记录而非答案切片,传统指标(Context Precision/Recall)失效。
建立分类型评估体系:
- 知识库检索用例 → Context Precision/Recall/Faithfulness
- 结构化 DB 查询用例 → 数据库查询准确性 + Answer Correctness
- Agent 模式专用指标 → 查询路径选择、工具调用准确性
1.6 综合优化建议
- 架构层面:多路召回融合(向量+关键词+结构化 DB+知识图谱);Agent 查询经验持续扩展。
- 数据层面:文档预处理增强(清理噪声、时效标记);图像识别针对印章/背景色/小字等场景优化。
- 评估层面:分类型评估体系;评测指标随架构演进而迭代。
二、从评测到产品:企业级智能体知识库的破局之路
上述评测实践揭示了一个深刻的事实:单一的 RAG 管道(切片→向量化→检索→生成)在企业级复杂场景下存在天然局限——时效性数据无法精准识别、图像与印章干扰难以克服、跨页信息整合困难、结构化数据查询不确定性高。
基于这些发现,边界智能打造了睿阁(ReKnow)企业级智能体知识库——它不是单纯做一个 RAG 知识库,而是将 Agent 智能体、MCP 协议、结构化数据库、混合检索等技术综合运用,从根本上突破传统 RAG 的能力边界。
2.1 产品定位:超越 RAG 的知识中枢
睿阁定位于企业级 AI 知识中枢,核心理念是「让正确的知识在正确的时机以正确的方式被获取」。与传统 RAG 的本质区别在于:睿阁不是一个固定的检索→生成管道,而是一个由 Agent 智能体驱动的、能根据查询特征自主选择最优知识获取路径的智能系统。
当用户询问「最新的LPR是多少」时,传统RAG可能返回旧版数据;而睿阁的 Agent 会自动识别这是一个时效性精准查询,直接路由到结构化数据库的lpr_history表,按时间降序获取最新记录。当询问“这笔贷款是否符合审批条件”时,Agent 则会走知识库检索+政策条款匹配的组合路径。这种基于查询意图的智能路由是睿阁与传统 RAG 的本质分界线。
2.2 核心技术架构:六大能力模块
2.2.1 Agent智能体——系统的「大脑」
- 意图识别与路径规划:判断查询类型,自动选择最优回答路径。
- 多步骤推理:将「最新LPR同比增长了多少」拆解为多步查询+计算。
- 工具调用决策:自动决策是否需要调用数据库、OCR、知识图谱等。
2.2.2 MCP(Model Context Protocol)——标准化连接协议
为 Agent 提供统一的工具调用接口,包括数据库 MCP、知识库 MCP、外部 API MCP。新增数据源只需实现对应的 MCP Server,大大降低扩展复杂度。
2.2.3 结构化数据库查询——从「模糊匹配」到「精准查询」
对于金融行业高频的数值类、时效性类查询,采用数据库查询替代传统RAG检索,从根本上消除不确定性。这正是评测中“V型反弹”的根本原因。
2.2.4 混合检索引擎——多路召回融合
- 向量语义检索 + 关键词精确匹配 + Reranker 重排序 + 知识图谱增强
- 多路召回的核心优势在于互补性,融合后的结果质量远高于任何单一检索方式。
2.2.5 安全合规体系
- 敏感信息自动识别与脱敏
- 基于角色的精细化权限控制
- RAG 投毒检测机制
- Prompt 注入攻击拦截
- 全链路审计日志
2.2.6 企业IM无缝集成——知识触手可及
睿阁提供与钉钉、飞书、企业微信等主流 IM 平台的无缝集成:
- IM机器人接入:员工无需离开 IM 即可提问,答案直接返回聊天窗口,支持@机器人、群聊协作问答。
- 单点登录与组织架构同步:与企业 IM 身份认证体系打通,自动同步组织架构和人员信息,实现基于部门和角色的细粒度权限控制。
- 消息卡片与富文本展示:答案以消息卡片形式呈现,支持 Markdown 渲染、表格展示、原文引用链接等。
- 工作流触发:将知识查询能力嵌入企业 IM 的审批流、通知流中——例如审批单据时自动关联政策依据,告警通知中附带处理指引。
- 多端一致性体验:PC 端、移动端、Web 端体验一致,确保外勤人员也能随时随地获取知识支持。
这种「把知识库搬到员工手边」的设计理念,从根本上降低了知识获取的门槛,大幅提升知识库的活跃使用率。
2.3 评测驱动的产品迭代
睿阁的研发严格遵循评测驱动开发理念,评测体系已产品化落地为内置质量监控模块:
- 自动化评测流水线,新知识入库后自动触发质量检测。
- 多维指标可视化仪表盘,实时掌握系统健康状态。
- 评测结果与告警联动,指标劣化时自动通知运维团队。
- 评测数据回灌优化,将评测发现转化为系统配置的持续调优。
2.4 行业实践价值
在金融行业首批客户实践中:
- 信贷政策问答:将分散在数百份文件中的政策、审批规则、利率信息整合为统一知识中枢,答案正确性从传统关键词检索的约60%,大幅提升至90–100%。
- 合规风控:自动识别并拦截敏感信息查询,对恶意诱导查询主动拒答,保障合规底线。
- 知识运营效率:新政策发布后可在分钟级完成知识入库和可用性验证,相比传统人工维护方式效率提升数倍。
2.5 未来展望
- Agent能力深化:从单轮问答进化为多步骤推理+自主决策。
- 多模态知识理解:扩展对图表、流程图、音视频等多模态知识的理解能力,解决评测中暴露的图像识别短板。
- 知识图谱融合:将向量检索与知识图谱推理深度结合,实现更深层次的语义理解和知识关联发现。
- MCP生态扩展:持续丰富MCP工具集,覆盖更多企业系统(ERP、CRM、OA等),打造真正的企业知识中枢。
- 行业标准化:推动RAG知识库评测标准在金融、政务等行业的标准化建设,为行业提供可复用的评测体系和最佳实践参考。
结语
RAG知识库的评测体系是企业级可用的基础工程。评测表明:单一优化效果有限甚至倒退,系统组合优化(Agent+结构化DB+混合检索+MCP)可产生显著协同增益。评测指标也需随架构演进迭代——Agent接入结构化DB后,传统检索指标的适用性需重新评估。
「睿阁」企业级智能体知识库从架构层面重新定义知识获取方式,通过Agent+MCP+结构化DB+混合检索的综合运用,将评测驱动的质量保障体系内化为产品核心能力,为金融、政务等行业提供可信赖的智能化知识服务。